
正規表現を使っていますか?
知ってるけどややこしくてよく分からないと言う人が多いと思います。
ややこしい事は抜きにして、手っ取り早く正規表現を使うために必要な事をお伝えします。
正規表現なんてワカラン・・・って感じで正規表現を使わないままなんてモッタイナイです。
ぜひぜひ正規表現を覚えましょう!
- 正規表現の全てを解説しているワケではありません。
- 正規表現を知らない人が、ややこしい事は抜きにして、まずは手っ取り早く使うことを目的にしてます。
正規表現はMacでもWindowsでもLinuxでもOS問わず使えます。
正規表現はOSやソフトより、エディタ等のソフトが外部使用(もしくは内蔵)する正規表現ライブラリに依存します。
ですので、お使いの環境で本記事の正規表現が期待した動きにならない事があります。
その場合、お使いのソフトや正規表現ライブラリ等のヘルプをご覧ください。
本文中、以下の2つが見分けにくいと思います。ご注意ください。
- / : スラッシュ
- \ : 円マーク(¥)
◆¥マークについて
Windowsでは円マーク(¥)を使いますが、Macではバックスラッシュ(\)を使います。
この記事ではバックスラッシュ( \ )という表記になっているかと思いますが、円マーク(¥)なのかバックスラッシュ(\)なのか、お使いの環境に合わせて読み替えてください。
Contents
正規表現ってなんじゃらほい?
こんにちは。kei(@boot_kt)です。
正規表現っていうのは一言で表すと、
- 文字列そのものじゃなくて形式(パターン)で表現する
- 複数の文字列(大体似てるけど微妙に違う)を一つの正規表現で表す
(あ、二言だ)
でもこれじゃ分かりにくいですよね。
次項で実際に使ってみましょう!
意味の理解は後回し。
まずは正規表現を使ってみよう!
手順1:この文章をテキストエディタにコピってください
↑上の文章をテキストエディタにコピってください。
Emacs、vi/Vim、Atom、Sublime Text、秀丸エディタ、サクラエディタ、YooEdit、褌エディット、mi、CotEditor等々・・・正規表現に対応しているエディタであればなんでもいいです。
手順2:上の文章から日付を検索してね
上の文章の中には以下の日付が入っています。
- 1999/2/4(Thurs)
- 2015/12/8( Tuesday )
- 2016/9/17(Sat )
- 2017/03/29(Wedn)
やりたい事としては、これらの 日付だけ を検索したいのです。
エディタによって違いますけど Ctrl + F もしくは command⌘ + F 、Emacsなら C + s、M – C – s、M – C – r で検索画面が出てくるはずです。検索の際は正規表現の設定してください。
↓を検索画面にコピってください。
\d{4}\/\d{1,2}\/\d{1,2}\(\s*[A-Z][a-z]+\s*\)
※2018/02/21訂正
[12][90][0-9][0-9]\/[0-9]*[0-9]\/[0-9]*[0-9]\(\s*[A-Z][a-z]+\s*\)
[12][90][0-9][0-9]\/([0-9][0-9]|[0-9])\/[0-9]*[0-9]\(\s*[A-Z][a-z]+\s*\)
[12][90][0-9][0-9]\/([0-9][0-9]|[0-9])\/([0-9][0-9]|[0-9])\(\s*[A-Z][a-z]+\s*\)
[12][90][0-9][0-9]\/[0-9]*[0-9]\/[0-9]*[0-9]\(\s*[A-Z][a-z]+\s*\)
↑微妙に意味は違うのですが、今回の検索においては全く同じ結果になります。
この正規表現で検索したら、検索したい全ての日付にヒットするでしょう。
なおかつ他の数字や日付もどきにはヒットしません。
ぜひやってみてください!
参考までに正規表現を使った検索をONにする設定を、幾つかのエディタでの方法を以下に書いておきます。
↓クリックすれば開きます。
Atomの正規表現検索
このボタンをONにします。

CotEditorの正規表現検索
このチェックをONにします。
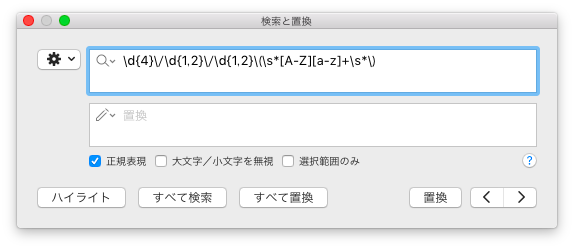
秀丸エディタの正規表現検索
このチェックをONにします。
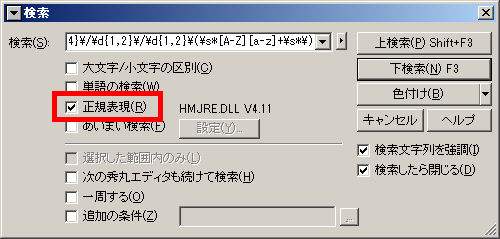
サクラエディタの正規表現検索
このチェックをONにします。
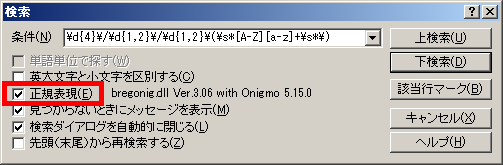
サクラエディタは別途正規表現用のDLLが必要です。
DLLが入っていないとこんなエラーが出ます。
サクラエディタの正規表現DLLはここからダウンロードできます。
サクラエディタ公式ページ → インストーラパッケージダウンロード → bregonig.dll
内容の解説
今回検索する日付をもう一度見てみましょう。
- 1999/2/4(Thurs)
- 2015/12/8( Tuesday )
- 2016/9/17(Sat )
- 2017/03/29(Wedn)
これらは似てはいますが、ビミョ~に違うんですよね。
テキストを検索するとき、この微妙に違うってのが面倒なんですよ。(この面倒さは経験者には分かるはず)
- 【年の部分】1999年も2000年代もある
- 【月の部分】2文字も1文字あり、しかも0が入る事もあれば入らない事もある
- 【日の部分】月の部分と同様
- 【曜日の部分】半角空白やタブスペースが入ることもあり入らないこともある
- 【曜日の部分】何文字なのかバラバラ
でも、共通する部分もあるんですよね。
- 【年の部分】4文字
- 【5文字目】年と月の間は /(スラッシュ)
- 【曜日の部分】前後は() カッコで閉じられている
- 【曜日の部分】1文字目は大文字のみ
- 【曜日の部分】2文字目以降は小文字のみ
正規表現を組み立てる時、この二つを考慮します。
- 共通する部分
- 共通しない部分
正規表現は全部を一気に見ると呪文みたいなんですけど、区切って見る と分かり易いと思います。
1個目の正規表現の説明
1個目の正規表現はこれなんですけど、
\d{4}\/\d{1,2}\/\d{1,2}\(\s*[A-Z][a-z]+\s*\)
これだけみても分かりにくいと思います。
↓こんな感じで区切って見ると良いと思います。区切ってみましょう。
\d{4} \/ \d{1,2} \/ \d{1,2} \( \s* [A-Z] [a-z]+ \s* \)
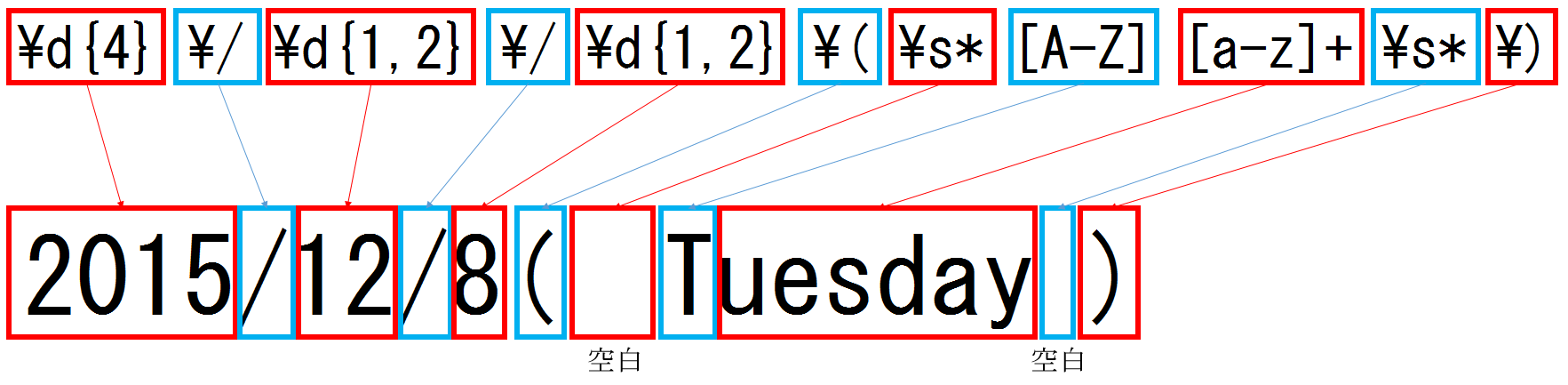
| どの部分? | 正規表現 | 説明 |
|---|---|---|
| 年の部分 | \d{4} | \d は [0-9]と同じです。要は0~9の数字を意味しています。
{4} は4文字連続という意味です。 |
| 年の部分と月の部分の間の/(スラッシュ) | \/ | /(スラッシュ)の文字表記そのものを表しています。/(スラッシュ)は正規表現の記号として使われているため、正規表現の記号ではなく /(スラッシュ)の文字そのものを表したい時は \ を付与します。 \ は エスケープ文字 とかって言われます。「エスケープ=束縛から逃げる」 という意味で、正規表現の記号からエスケープ(逃げる)すると考えてください。 |
| 月の部分 | \d{1,2} | \d は数字(0~9)を意味しています。 {1,2} は直前の文字(この場合は \d )が1回以上2回以内の登場を意味しています。 |
| 月の部分と日の部分の間の /(スラッシュ) | \/ | (※省略:前述済み) |
| 日の部分 | \d{1,2} | (※省略:前述済み) |
| 曜日の部分の前の ( | \( | \/ と同じく、((カッコ)の文字表記そのものを表しています。 |
| 曜日の部分(前の空白のチェック) | \s* | \s は空白です。スペースの「s」ですかね。 半角空白やタブや改行を期待します。 全角空白にはヒットしません。 * は直前の文字(この場合は \s )が0文字以上という意味です。 無くてもいいなら、じゃぁ指定する必要は無いんじゃないの?と思うかも知れませんが、あった時にその存在を判断できる正規表現が無いので正しくチェックできないのです。なので、0文字以上というのは結構重要です。 |
| 曜日の部分(1文字目) | [A-Z] | [A-Z] は大文字のA~Zを表します。
そもそも [ ] 自体についてですが、このカッコの中に書いた文字のどれかにヒットすればOKというものです。 - は単に間を書くのを省略しているだけです。ABCDE・・・・Z と書くと長くて面倒なので A-Z と省略して書いているだけです。 |
| 曜日の部分(2文字目以降) | [a-z]+ | [a-z] は上の [A-Z] と同じですが、小文字のa~zという意味になります。
+ は直前の文字(この場合は [a-z] )が1文字以上という意味です。 |
| 曜日の部分(後ろの空白のチェック) | \s* | (※省略:前述済み) |
| 曜日の部分の後ろの ) | \) | \( と同じく、)(カッコ)の文字表記そのものを表しています。 |
2個目の正規表現の説明
1個目の正規表現とそんなに大差無いですが、微妙に違うのでその部分に注目してください。
2個目の正規表現はこれなんですけど、
[12][90][0-9][0-9]\/[0-9]*[0-9]\/[0-9]*[0-9]\(\s*[A-Z][a-z]+\s*\)
↓これも区切ってみましょう。
[12] [90] [0-9] [0-9] \/ [0-9]* [0-9] \/ [0-9]* [0-9] \( \s* [A-Z] [a-z]+ \s* \)
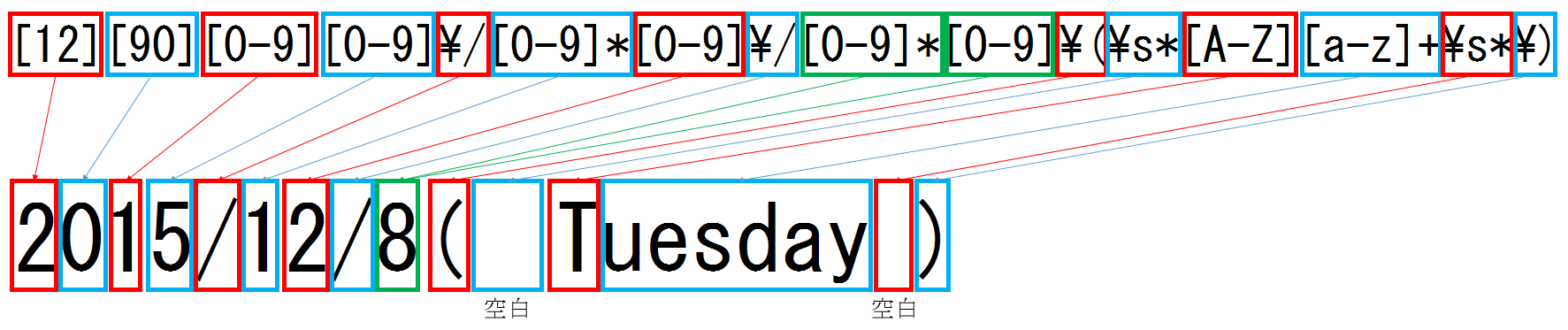
| どの部分? | 正規表現 | 説明 |
|---|---|---|
| 年の部分(1桁目) | [12] | [ ] 自体がこのカッコの中に書いた文字のどれかにヒットすればOKというものですが、この場合は1もしくは2を期待するというものです。
今回の文章の日付は1900年代もしくは2000年代と分かっているので、年の1桁目は1か2だけとなります。3000年代とか4000年代は無いと分かりきっているのでそうしています。 |
| 年の部分(2桁目) | [90] | [12] と同じく、9もくは0を期待するものです。
今回の文章の日付は1900年代と2000年代と分かっているので、年の2桁目は9か0だけとなります。1800年代とか2100年代は無いと分かりきっているのでそうしています。 |
| 年の部分(3桁目) | [0-9] | [ ] 自体がこのカッコの中に書いた文字のどれかにヒットすればOKというものですが、0~9を期待するものです。 [0123456789] と書いてもいいですけど、面倒なので [0-9] と省略して書いているだけです。 |
| 年の部分(4桁目) | [0-9] | (※省略:前述済み) |
| 月の部分と日の部分の間の /(スラッシュ) | \/ | \ はエスケープ文字ですので、\/ は /(スラッシュ)の文字表記そのものを意味しています。 |
| 月の部分(1桁目) | [0-9]* | [0-9] については「年の部分(3桁目)」を参照してください。 * は1個目の正規表現の解説の「曜日の部分(前の空白のチェック)」を参照ください。 |
| 月の部分(2桁目) | [0-9] | (※省略:前述済み) |
| 月の部分と日の部分の間の /(スラッシュ) | \/ | (※省略:前述済み) |
| 日の部分(1桁目) | [0-9]* | (※省略:前述済み) |
| 日の部分(2桁目) | [0-9] | (※省略:前述済み) |
| 曜日の部分の前の ( | \( | (※省略:前述済み) |
| 曜日の部分(前の空白のチェック) | \s* | (※省略:前述済み) |
| 曜日の部分(1文字目) | [A-Z] | (※省略:前述済み) |
| 曜日の部分(2文字目以降) | [a-z]+ | (※省略:前述済み) |
| 曜日の部分(後ろの空白のチェック) | \s* | (※省略:前述済み) |
| 曜日の部分の後ろの ) | \) | (※省略:前述済み) |
正規表現ってどんな時に使うの?
- 大量のテキストを検索する時
- 大量のテキストを置換する時
- プログラミングで、入力チェックする時
正規表現はテキストをパターン化したもので、主にテキストの検索や置換の時に力を発揮します。ファイル名を探すときにも使えます。
UNIX系であればコマンドを打ってその結果を正規表現で整理するということも可能です。
膨大なテキストデータの解析にも使えるでしょう。
また、プログラミングにおいて入力項目のチェックにも使えます。(これが特に超便利!!!)
正規表現って他にはどんな書き方ができるの?
私も全てを知っているわけではありませんが、以下の内容を覚えておけば役立つと思います。
覚えておきたい基本の書き方
| 正規表現 | 内容 | 書き方例 |
|---|---|---|
| [ ] | [ ] 内の文字のいずれかにヒットすればOK |
|
| [^] | 否定:[ ] 内の文字以外を意味します。 |
|
| ( ) | グループ:連続した文字を探す場合に使われます。 |
|
| ^ | 行頭:行の1文字目という意味です。文章の途中からではなく、行の先頭から始まっているものを探したい時に使います。 | abcという文字列:(^abc) |
| $ | 行末:行の最後を指定します。文章の途中ではなく、文章の終わりにあると分かっているときに使います。 | abcという一行(文の途中はヒットしません):^abc$ |
| . | 任意の一文字:なんでもいいので文字が一文字あればという意味です。 |
|
| * | 直前の文字やパターンが0個以上という意味 |
|
| + | 直前の文字やパターンが1個以上という意味 | abcABCd、abcabcABCABCd、abcabcABCd、abcABCABCdにヒット:(abc)+(ABC)+d+ |
| ? | 直前の文字やパターンが0個もしくは1個。2個以上はダメ。 |
|
| | | OR条件 | AAAabcBBB、AAAdefBBBにヒット:AAA(abc|def)BBB |
覚えておきたいエスケープ文字1
| 改行 | \n |
| タブ | \t |
| \\ | \ そのもの |
| \[ | [ そのもの |
| \] | ] そのもの |
| \( | ( そのもの |
| \) | ) そのもの |
| \{ | { そのもの |
| \} | } そのもの |
| \^ | ^ そのもの |
| \$ | $ そのもの |
| \. | . そのもの |
| \* | * そのもの |
| \+ | + そのもの |
| \? | ? そのもの |
| \| | | そのもの |
覚えておきたいエスケープ文字2
| \s | スペースのs:半角スペース、タブスペース、改行 |
| \S | \S 以外:通常の文字です |
| \d | decimalのd:[0-9] と同じ |
| \D | \d以外:[^0-9] と同じ |
| \c | [a-zA-Z0-9] と同じ |
| \i | [a-zA-Z]と同じ |
| \y | 単語の区切り |
| \w | word:単語 |
| \< | 単語の始まり |
| \> | 単語の終わり |
覚えておきたい回数指定
| {n} | n回 |
| {n,} | n回以上 |
| {n,m} | n回以上、m回以下 |
正規表現をプログラミングの中で使うには
正規表現はテキストを検索するだけではありません。
プログラミングでも使えます。
例えば、ある入力項目があるとします。
Webアプリやフォームでもいいです、生年月日とか日付を入力する項目があったとして、その日付の正当性をチェックする必要がありますよね。
日付なのに「201a/11/23」って入力されるとダメだし、かと言って「1715/11/23」「4000/11/23」みたいにトンデモナイ過去や未来の日付を入力されても困るし、「2000/11/42」みたいなあり得ない日付を入れられても困ります。
で、日付の形式チェックをしようと思うと結構大変。
全てのエラーチェックを書くのはめちゃくちゃ大変です。
日付でチェックすべき項目をざっと挙げると、こんな感じでしょうか?
- 数字以外は入っていないか?
- 記号は入っていないか?
- 全角数字は入っていないか?
- 年は4桁か?
- 月は2桁か?(1桁なら0埋めが必要な時不要な時の判断が必要)
- 日は2桁か?(1桁なら0埋めが必要な時不要な時の判断が必要)
- スラッシュは入っているか?
これらをイチイチif命令を使って判断しまくるのは超面倒です。
プログラムを書くだけならまだしも、テストもかなり面倒です。
もぅマジ無理・・・定時退社しよ・・・・
って感じになってしまいます。
それを正規表現で書くとたった一行でチェックできちゃうので超便利ですよ。
ホント!
- 正規表現でチェックできるのはあくまでも形式なので正当性とかはまた別途チェックが必要です。
- うるう年については正規表現では分からないので別途チェックする必要があります。(正規表現でうるう年チェックをできない事はないと思いますが、面倒なのでやらない方がいいと思います)
- プログラム言語によっては日付用のクラスや関数が準備されていて、正規表現を使うまでもなく日付チェックすることは可能です。
RubyとかC++とかJavaとかPHPとかPerlとかPythonとかシェルとかDOSバッチとか、大抵のプログラム言語は正規表現をサポートしていますし、チェックも可能です。
上に書いたような日付の形式チェックをプログラミングすると結構な量を書く必要がありますが、正規表現だと一行で済みます。
↓Rubyならこんな感じ
target_txt = "1999/2/4(Thurs)"
reg_txt = Regexp.new(/\d{4}\/\d{1,2}\/\d{1,2}\(\s*[A-Z][a-z]+\s*\)/)
if target_txt =~ reg_txt
puts("Match!")
else
puts("No match")
end
オススメのツール
Atomの正規表現プラグイン
Atomでも正規表現のプラグイン(パッケージ)があります。
それは regex-railroad-diagram package です!
これ超便利!!!
自分で書いた正規表現がグラフィカル(?)に見えるんですよ!!!
これは絶対入れるべき!!!
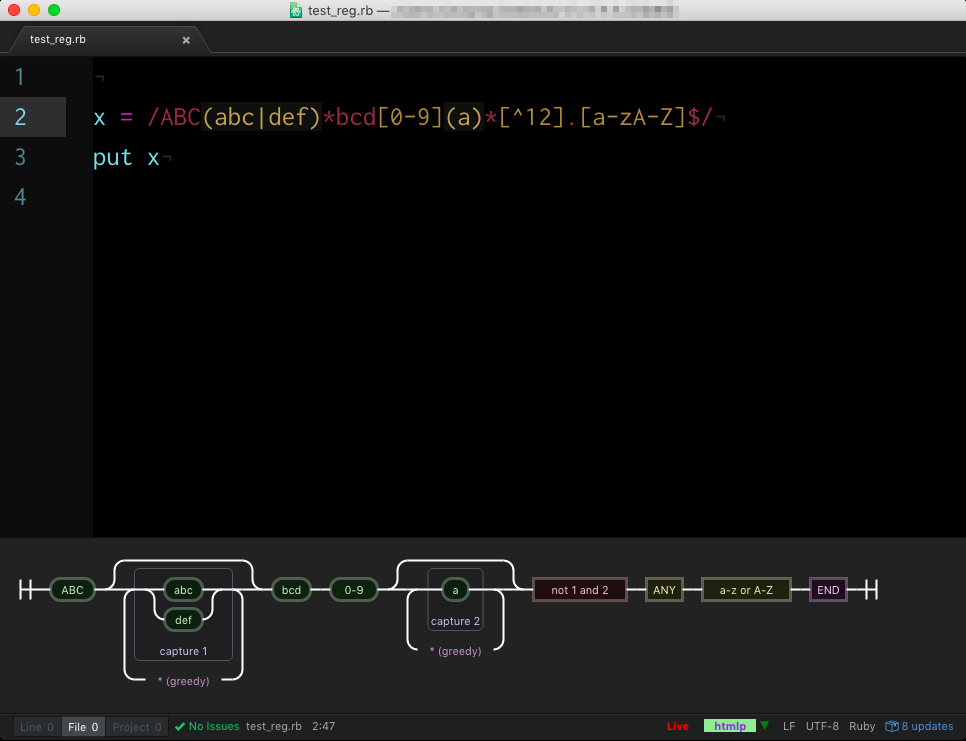
使い方
- インストール
- プログラムを書く
- プログラムの中に正規表現を書く
- 正規表現の中にカーソルを置く
- 画面下に自動的に正規表現のダイアグラムが表示
※もしエラーらしきものが出たら間違っているので見直しましょう!
自分が書いた正規表現がグラフィカルに表示されるので、どのような文字列ならヒットするのかがめちゃくちゃ分かり易いです。
正規表現に慣れていない時はこれを使うと正規表現のカンが養われると思いますよ。
regex-railroad はどうも前後がスラッシュで囲まれているものを正規表現として見ているようです。
ダブルクォーテーションで囲むと正規表現として認識してくれないみたいです。
お気を付けください。
設定で調整できるのかも知れませんが、使い始めたところで細かい設定が分からないです。
ゴメンナサイ。
秀丸エディタ
私は秀丸エディタを使っているのですが、秀丸エディタの検索画面が便利なんです。
正規表現の一覧みたいなのが出てくれるのでものすごく助かります。
正規表現の全てを覚えていればいいんですけど、思い出せないこともあるんですけど、検索画面ですぐに見られるので超便利なんです。
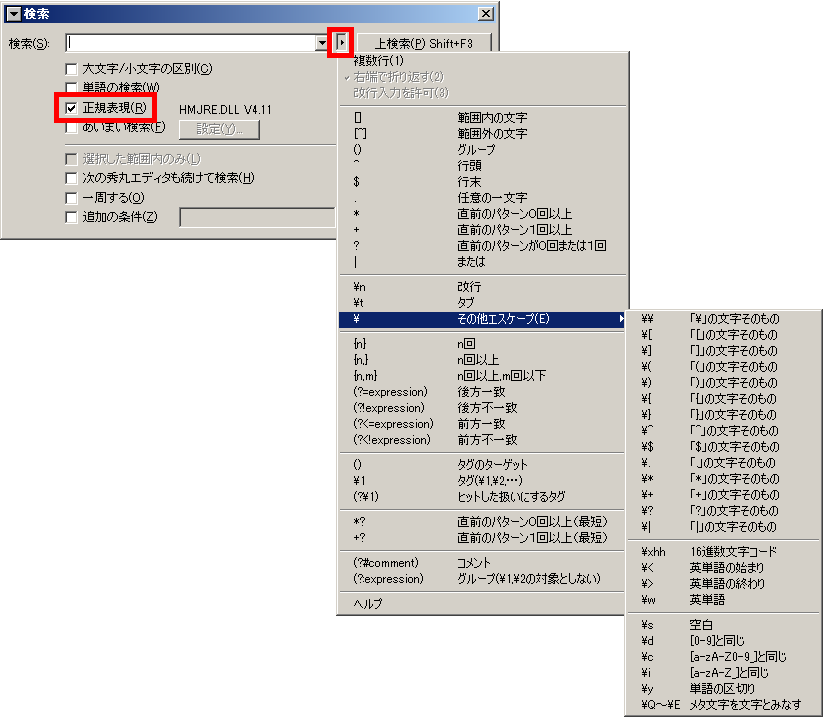
と言っても覚える事はそんなに多くはないですけどね。
まとめ
何に使うのかワカラン!
ってか、使う必要無いでしょ
そもそも何を書いてるのか読めないし、どう書けばいいのかもワカラン!
呪文じゃん!!!
と思う人は多いのではないでしょうか。
でも使い出すと便利さがよく分かると思います。
特にプログラミングで使うと非常に便利です。
電話番号のチェック、日付のチェック、時刻のチェック、書類番号のチェック、メールアドレスのチェック等々・・・・、プログラミングにおいては色々な文字列や番号等のチェックが必要になります。
そのときに正規表現を使えば一行でできてしまうのです。
正規表現使わずにまともにチェックしてるとドエライことになりますよ。
私も正規表現はそんなに詳しくないのですが、積極的に使うようにしています。
プログラミングの入力チェックでは必ずと言っていいほど正規表現を使ってチェックします。
テストも楽になりますしね。
あと、正規表現を覚えておくとテキストの検索や置換がすごくラクチンになりますので、検索漏れとかがなくなります。
プログラミングをする人はもちろん、プログラミングをしない人でもテキストを使うことが多いのであれば、正規表現はきっと役に立ちます。
ホンットに正規表現を使ってみてください!
便利ですから!
思っているほど難しくないですよ。
結構カンタンですよ。
いや、、、、、
かなりカンタンです!
参考書籍





atomだと2つ目の正規表現だと「2017/033/29(Wedn)」これも検索されてしまいませんか?
「[12][90][0-9][0-9]\/([0-9][0-9]|[0-9])\/[0-9]*[0-9]\(\s*[A-Z][a-z]+\s*\)」こんな感じでは?
ご指摘ありがとうございます!!
おっしゃる通りです。
提示頂いた正規表現が正解ですね。
直しておきます。
↓こんな感じでもいいかと思います。
[12][90][0-9][0-9]\/[0-9]?[0-9]\/[0-9]?[0-9]\(\s*[A-Z][a-z]+\s*\)
修正ありがとうございます
自分のは載せないでも平気ですよ(-_-;)